
- ผู้เขียน John Day day@howwhatproduce.com.
- Public 2024-01-30 13:04.
- แก้ไขล่าสุด 2025-01-23 15:12.

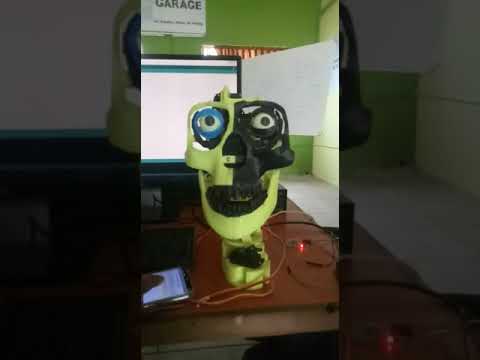
Mona เป็นหุ่นยนต์ AI ที่ใช้ watson Ai เป็นพื้นหลัง เมื่อฉันเริ่มโครงการนี้ มันดูซับซ้อนกว่าที่ฉันคิดไว้มาก แต่เมื่อฉันเริ่มทำงาน คลาสความรู้ความเข้าใจของ ibm (ลงทะเบียนที่นี่) ช่วยฉันได้มาก ถ้าคุณต้องการ คุณสามารถทำได้ เข้าชั้นเรียนตอนนี้หรืออย่างอื่นเพียงแค่ดำเนินการต่อกับคำแนะนำนี้
ฉันต้องการบอทของฉันเพื่อตอบสนองต่อสิ่งต่อไปนี้
1. เมื่อฉันพูด
2.เมื่อต้องการพูด
3.เมื่อต้องการควบคุมการเคลื่อนไหวของตา/กราม…ฯลฯ
ดังนั้น เมื่อฉันพูด ควรแปลงคำพูดของฉันเป็นข้อความ จากนั้นควรตรวจสอบในฐานข้อมูล (เอนทิตี / เหตุการณ์ /) จากนั้นจะต้องพูดคำตอบเช่นข้อความเป็นคำพูด
ดังนั้นคุณต้องการสิ่งด้านล่าง
ก่อนใช้บริการด้านล่าง กรุณาสร้างบัญชี IBM Bluemix
1.ข้อความเป็นคำพูด
2.พูดเป็นข้อความ
3.ผู้ช่วยวัตสัน
ขั้นตอนที่ 1: เตรียมสิ่งของของคุณ
1.ราสเบอร์รี่ปี่.
2.ไมค์
3.ลำโพง
กะโหลกศีรษะ (พิมพ์ 3d):
ไฟล์ 3D Printing สามารถพบได้ที่นี่:คลิกที่นี่
และเหนือสิ่งอื่นใด คุณควรมีการเชื่อมต่ออินเทอร์เน็ตที่เหมาะสม…………
ตอนนี้ฉันกำลังจะใช้ราสเบอร์รี่ pi เพื่อประมวลผลทั้งหมด
หากคุณเคยใช้ Raspberry Pi มาก่อน ให้ติดตั้ง Node.js และไปที่ขั้นตอนถัดไป
มิฉะนั้น ให้ทำตามคำแนะนำด้านล่างเพื่อตั้งค่า Pi ของคุณ:
การเริ่มต้นใช้งาน Pi Raspberry Pi นั้นคล้ายกับคอมพิวเตอร์ทั้งเครื่อง ซึ่งหมายความว่าคุณต้องมีจอภาพ เมาส์ และคีย์บอร์ดสำหรับมัน หากคุณมีทีวีอยู่ใกล้ๆ คุณสามารถเชื่อมต่อ Pi กับทีวีผ่านสาย HDMI ในชุดอุปกรณ์ Pi ส่วนใหญ่ การ์ด SD ได้รับการโหลดไว้ล่วงหน้าด้วยภาพของระบบปฏิบัติการ Raspberry Pi คุณต้องใส่การ์ด SD ลงใน Pi เปิด Pi และทำตามคำแนะนำบนหน้าจอเพื่อทำการติดตั้งระบบปฏิบัติการให้เสร็จสิ้น หากคุณมีปัญหาในการตั้งค่า Pi คุณสามารถแก้ไขปัญหาได้ที่นี่
ติดตั้งแพ็คเกจ เปิดแอปพลิเคชั่นเทอร์มินัลบน Pi และรันคำสั่งต่อไปนี้เพื่อติดตั้ง Node.js และ npm เวอร์ชันล่าสุด (Node Package Manager)
คุณต้องใช้แพ็คเกจเหล่านี้ในภายหลังเพื่อเรียกใช้โค้ดของคุณ
curl -sL https://ibm.biz/tjbot-bootstrap | sudo sh
เสียบไมโครโฟน USB และลำโพงของคุณ
ขึ้นอยู่กับแหล่งสัญญาณเสียงออกที่คุณใช้กับ Pi (HDMI, แจ็คเสียง 3.5 มม., Bluetooth, ลำโพง USB) คุณอาจต้องตั้งค่าคอนฟิกเสียง
แจ็คเสียง HDMI/ 3.5 มม. หากคุณใช้แจ็คเสียง HDMI หรือ 3.5 มม. คุณอาจต้องตั้งค่าการกำหนดค่าเสียง ในการดำเนินการนี้ ให้ไปที่เทอร์มินัลแล้วเปิด raspi-config
sudo raspi-config
ซึ่งจะเปิดหน้าจอการกำหนดค่า Raspberry Pi
เลือก "ตัวเลือกขั้นสูง" แล้วกด Enter จากนั้นเลือก "เสียง" แล้วกด Enter เลือกช่องสัญญาณที่ถูกต้องสำหรับเสียงที่ส่งออก หากคุณเชื่อมต่อลำโพงภายนอกเข้ากับแจ็คเสียง คุณควรเลือกแจ็ค 3.5 มม.
ลำโพง USB:
หากคุณมีเสียง USB คุณต้องอัปเดต /usr/share/alsa/alsa.config เพื่อตั้งค่าเสียง USB เป็นอุปกรณ์เริ่มต้น เริ่มต้นด้วยการเรียกใช้คำสั่งต่อไปนี้เพื่อให้แน่ใจว่า USB ของคุณเชื่อมต่อและแสดงรายการอยู่ที่นั่น
lsusb
ถัดไปคือการตรวจสอบหมายเลขการ์ดของ USB audio.aplay -l
จดหมายเลขการ์ดที่เชื่อมโยงกับ USB Audio ของคุณ
จากนั้นไปที่ไฟล์ alsa.config เพื่อตั้งค่าเป็นค่าเริ่มต้น
sudo nano /usr/share/alsa/alsa.conf
มองหา
defaults.ctl.card 0
defaults.pcm.card 0
และอัปเดตหมายเลขการ์ด (0 ที่นี่) เป็นหมายเลขการ์ดของเสียง USB ของคุณ
Raspberry Pi OS เวอร์ชันต่างๆ อาจต้องมีการตั้งค่าที่แตกต่างกัน หากคุณมีปัญหากับการตั้งค่า USB ให้อ่านคู่มือนี้เพื่อแก้ไขปัญหา
ขั้นตอนที่ 2: รหัส Git-hub
ซอร์สโค้ดมีอยู่ที่ github ดาวน์โหลดหรือโคลนโค้ดและรันคำสั่งต่อไปนี้จากเทอร์มินัลเพื่อติดตั้งการขึ้นต่อกัน ต่อไปนี้คือคำแนะนำสำหรับวิธีโคลนที่เก็บจาก github หากคุณยังไม่เคยทำมาก่อน
โคลน git
cd mona/สูตร/บทสนทนา
npm ติดตั้ง
เคล็ดลับสำหรับมือโปร: หากคุณได้รับข้อผิดพลาดสำหรับการติดตั้ง npm ที่แจ้งว่าไม่พบ npm คุณควรติดตั้ง npm บนเครื่องของคุณก่อน นี่คือบรรทัดคำสั่งสำหรับติดตั้ง npm
sudo apt-get ติดตั้ง npm
ในขั้นตอนนี้ เราช่วยให้คุณเข้าถึง API ของบริการสนทนาสามบริการ:
(1) คำพูดเป็นข้อความ
(2) ผู้ช่วยวัตสัน
(3) ข้อความเป็นคำพูด
คุณต้องคัดลอกข้อมูลประจำตัวของคุณสำหรับบริการเหล่านี้ทั้งหมด สร้างอินสแตนซ์ของบริการ Watson Assistant, Speech to Text และ Text to Speech และจดข้อมูลรับรองการตรวจสอบสิทธิ์
นำเข้าเวิร์กสเปซ-sample.json
ไฟล์ลงในบริการ Watson Assistant และจดบันทึก ID พื้นที่ทำงาน
ทำสำเนาไฟล์การกำหนดค่าเริ่มต้นและอัปเดตด้วยข้อมูลรับรองบริการ Watson และ ID พื้นที่ทำงานการสนทนา
$ sudo cp config.default.js config.js
$ sudo nano config.js
ขั้นตอนที่ 3: เรียกใช้รหัส
ตอนนี้คุณพร้อมที่จะคุยกับ TJBot แล้ว!
เปิดเทอร์มินัลแล้วรันคำสั่งต่อไปนี้:
sudo node conversation.js
การสนทนาของวัตสันใช้เจตนาเพื่อระบุจุดประสงค์ของประโยค
ตัวอย่างเช่น เมื่อคุณถามโมนาว่า "ได้โปรดแนะนำตัวเอง" เจตนาคือการแนะนำตัว
คุณสามารถเพิ่ม Intents ใหม่ของคุณเองได้ในเครื่องมือแก้ไขการสนทนา แต่สำหรับตอนนี้ เราได้เริ่มต้นให้คุณด้วยความตั้งใจสองสามอย่าง: บทนำ
คุณสามารถพูดวลีเช่น "วัตสัน กรุณาแนะนำตัวเอง", "วัตสัน คุณเป็นใคร" และ "วัตสัน แนะนำตัวเองหน่อยได้ไหม"เรื่องตลก
คุณสามารถถาม "วัตสัน ช่วยเล่าเรื่องตลกให้ฉันฟังหน่อย" หรือ "วัตสัน ฉันอยากฟังเรื่องตลก"
สำหรับรายการทั้งหมด ให้ตรวจสอบเนื้อหาของ workspace-sample.json
ใช้คำให้ความสนใจเพื่อให้ Mona รู้ว่าคุณกำลังคุยกับเขา
คำแสดงความสนใจเริ่มต้นคือ 'Watson' แต่คุณสามารถเปลี่ยนได้ใน config.js ดังนี้
อัปเดตไฟล์การกำหนดค่าเพื่อเปลี่ยนชื่อหุ่นยนต์ในส่วน tjConfig: // ตั้งค่าการกำหนดค่าของ TJBot
exports.tjConfig = {
บันทึก: { ระดับ: 'verbose' },
หุ่นยนต์: { ชื่อ: 'ตี๋ เจย์ บอท' }
};
คุณสามารถเปลี่ยน 'ชื่อ' เป็นอะไรก็ได้ที่คุณต้องการเรียกว่า "โมนา" นอกจากนี้ หากคุณเปลี่ยนเพศเป็น 'ผู้หญิง' TJBot จะใช้เสียงผู้หญิงพูดกับคุณ! สนุก!
มีโอกาสดีที่หนึ่งในสองสิ่งนี้เกิดขึ้น: (1) เอาต์พุตเสียงถูกนำไปยังช่องสัญญาณที่ไม่ถูกต้อง (คุณสามารถแก้ไขได้จาก raspi-config) (2) โมดูลเสียงของคุณถูกบล็อก
ในกรณีนั้น ให้ไปที่ /etc/modprobe.d/ และลบ blacklist-rgb-led.conf จากนั้นรันคำสั่งต่อไปนี้:
sudo update-initramfs -u
รีบูตและยืนยันว่าโมดูล "snd" กำลังทำงานโดยดำเนินการคำสั่ง "lsmod"
สิ่งนี้ควรแก้ปัญหา lsmod
แนะนำ:
"ไฮไฟว์" หุ่นยนต์ Cardboard Micro:bit: 18 ขั้นตอน (พร้อมรูปภาพ)
")
"ไฮไฟว์" หุ่นยนต์ Cardboard Micro:bit: ติดอยู่ที่บ้าน แต่ยังต้องการไฮไฟว์ใครสักคน? เราสร้างหุ่นยนต์ตัวน้อยที่เป็นมิตรด้วยกระดาษแข็งและ micro:bit พร้อมด้วย Crazy Circuits Bit Board และทั้งหมดที่เธอต้องการจากคุณคือการไฮไฟว์เพื่อให้ความรักที่เธอมีต่อคุณมีชีวิตอยู่ ถ้าคุณชอบ
หุ่นยนต์ ShotBot: 11 ขั้นตอน

ShotBot Robot: คำแนะนำนี้ถูกสร้างขึ้นเพื่อตอบสนองความต้องการของโครงการ Makecourse ที่มหาวิทยาลัยเซาท์ฟลอริดา (www.makecourse.com)
หุ่นยนต์ Telepresence ขนาดมนุษย์พร้อมแขนจับ: 5 ขั้นตอน (พร้อมรูปภาพ)
")
หุ่นยนต์ Telepresence ขนาดมนุษย์พร้อมแขนกริปเปอร์: MANIFESTOA ความคลั่งไคล้ของฉันเชิญฉันไปที่งานปาร์ตี้ฮัลโลวีน (30+ คน) ระหว่างการระบาดใหญ่ ดังนั้นฉันจึงบอกเขาว่าฉันจะเข้าร่วมและออกแบบหุ่นยนต์ telepresence เพื่อสร้างความหายนะในงานปาร์ตี้ สถานที่. หากคุณไม่คุ้นเคยกับสิ่งที่โทร
หุ่นยนต์ DMX Animatronic: 9 ขั้นตอน (พร้อมรูปภาพ)
")
หุ่นยนต์ DMX Animatronic: โปรเจ็กต์นี้อธิบายการพัฒนาต้นแบบแอนิมาโทรนิกที่ทำงานได้อย่างสมบูรณ์ มีการใช้งานตั้งแต่เริ่มต้นและมีเป้าหมายเพื่อเป็นแนวทางในการพัฒนาหุ่นยนต์แอนิมาโทรนิกที่มีความซับซ้อนมากขึ้นในอนาคต ระบบนี้ใช้ไมโครคอนโทรล Arduino
หุ่นยนต์ทรงตัว / หุ่นยนต์ 3 ล้อ / หุ่นยนต์ STEM: 8 ขั้นตอน

หุ่นยนต์ทรงตัว / หุ่นยนต์ 3 ล้อ / หุ่นยนต์ STEM: เราได้สร้างหุ่นยนต์ทรงตัวแบบผสมผสานและ 3 ล้อสำหรับใช้ในการศึกษาในโรงเรียนและโปรแกรมการศึกษาหลังเลิกเรียน หุ่นยนต์นี้ใช้ Arduino Uno, ชิลด์แบบกำหนดเอง (รายละเอียดการก่อสร้างทั้งหมดที่มีให้), ชุดแบตเตอรี่ Li Ion (ข้อจำกัดทั้งหมด